


As of today, OpenAI's GPT-4 is a good first model to try for many tasks and might fit most developer needs. Try it, and if it meets your needs, use it. If it does not meet your needs, you need to evaluate other models and pick one. This article shows you how to do that.
I wrote an earlier article on how to pick a chat model for interactive use from the web interface. Trying out the models interactively can help to pick the corresponding chat model API to use in your programs. However, keep in mind that some API models require you to get on a waitlist and get approved, and all the things you can do interactively are not always available from the corresponding APIs.
Ideally, you want to evaluate the models on your customer's data and see which one works best. You would gather a lot of data representative of your customers' data distribution, annotate it, build a benchmark based on that, and use (human or LLM) evaluation to compare and pick the best generative model for our use case. If you have a lot of customer data that represents your customers well and have a feasible path to get it annotated and evaluated, this is the best approach. However, if you are building an early product, and do not have much customer data to validate against, this may be less effective. The data may also change a lot from assumed early data to production data. Even if you have data, annotating them with ground truth answers may be time-consuming and introduce the subjectivity of the evaluators. For such reasons, this approach, though ideal, may not be feasible for many people.
In that case, we can fall back to using an industry benchmark evaluated using some systematic scientific evaluation system. Benchmarks have some advantages. Good benchmarks use a lot of carefully curated data to cover a wide range of distributions. Carefully chosen evaluation systems can also wipe out individual evaluators' biases by averaging across a lot of evaluations on the same data points. A good benchmark is MT-bench, and a good evaluation system is lmsys chat arena.
lmsys chat arena is a place where human volunteers can compare answers head to head between two models and pick which they like better. These evaluations are then aggregated to evaluate models using the Elo rating system - this is the system used to rank, for instance, chess players, where each player plays against other players, and their rank increases or decreases based on the ranking of the opponent they played and the outcome of each game. The lmsys chat arena and leaderboard use the same system to rank models through head-to-head evaluations by human volunteers.
The MT-Bench dataset categorizes each test by different tasks such as writing, roleplay, reasoning, math, coding, extraction, STEM and humanities.
Some popular chat models are OpenAI's gpt-4, Anthropic's claude(v2), Google's chat-bison, Meta's llama-2-70b. You can find a comparison of these and many other chat models in this lmsys chatbot arena leaderboard.
You can also get a radar chart that compares these models on various tasks in this Colab notebook (linked from the llm-judge Github repo). You can modify the code in the notebook to change the models used, the tasks considered, etc. In the notebook, hovering on each point in the plot shows you the model and its score and details.
A radar chart with all the currently compared models as of today is shown below (generated with simple changes to the above-linked Colab).
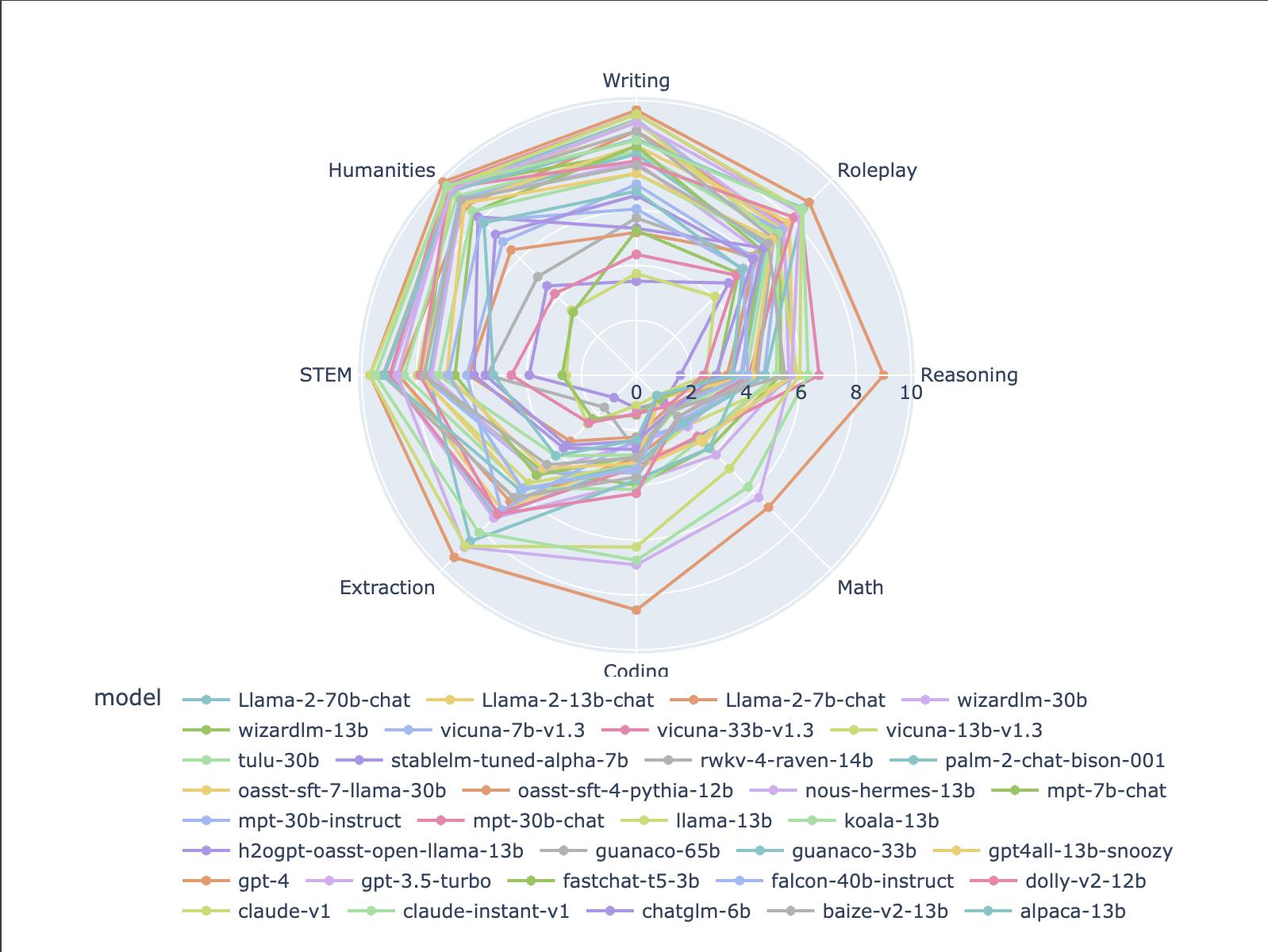
It shows that GPT-4 still excels at reasoning, coding, math and extraction, but other models are comparable on other tasks and fast catching up.
Benchmarks and evaluations also have limitations. There may be errors in the annotations of data. These are often detected much later. Newer models may be trained on benchmark data, making them perform better on the benchmarks than they would without it. Conversely, benchmarks are built to challenge models at the time of their creation and hence make it harder for those earlier models to beat them than newer models. There might be less data overall on newer models than older ones, skewing their results due to higher variance than models with more data. The evaluation system, when it has less data on some comparisons, may allow the biases of the evaluators to creep into the outcomes. So, all benchmark results and rankings should be analyzed with a lot of scrutiny to see how much we can trust each hypothesis.
Nevertheless, in the absence of other criteria, the benchmarks provide us with a valuable tool to compare and evaluate models, when custom evaluations are infeasible.
Other considerations
The performance of a model may change over time. This could be due to the ongoing changes in the model based on other criteria (such as safety). See this paper and this podcast episode for a fascinating analysis and hypotheses on the change in the performance of ChatGPT models over time. So, we need to check back from time to time to see if the models are still performing as they were before.
The performance of a model alone does not determine its fit for your use case. We need to consider tradeoffs with other factors while picking a model.
All generative models are restricted by the last date when they were trained, called the knowledge cutoff date. If your use case needs more up-to-date knowledge, you may need to pick a different model.
Training a generative model is expensive and takes a long time, so research has found effective techniques to update models with newer information without having to train them completely. A technique called Lora and its variants are popular, and there are other techniques as well. See this video to understand some of these approaches as applied to image models (but some of those ideas are used with text models as well).
Some higher-performing models may be slow, flaky or less robust than others.
All hosted models impose rate limits, and the rate limits provided may not fit your needs. On the other hand, self-hosting comes with additional costs, both initial and ongoing. The performance gap between hosted models and self-hosted models is closing due to several quantization tricks (using lower precision numbers for weights to reduce model size) and model distillation techniques, many based on student-teacher distillation (training a much smaller student model in conjunction with the larger teacher model, and then using the student model). A recent model called Zephyr-7B uses a form of student-teacher distillation (among other things) to create a model that performs as well as a much larger model. See the paper.
Another important consideration for generative models is alignment - how well the model's responses align with the user's intent and expectations. Sometimes, the problem is underspecified expectations - for example, if a product asks a model to summarize some text, the ideal summary for an expert on the topic of the text is very different from the ideal summary for a novice. These need to be addressed with the proper UI design that may include providing more information about the expectations while asking the model. In other cases, the model provides completely irrelevant responses that are highly misaligned with the user intent. Here, it might be useful to test different models qualitatively with different types of users and then pick the model that works best.
An important facet of model alignment is the safety of the model response. All generative models may provide wrong, biased, dangerous or otherwise inappropriate results, so it is a good idea to warn your customers to be prepared for that. Some models have taken more effort to be safe, while some models are inherently less safe. Techniques used to make models safer are an ongoing area of research, and many models are fine-tuned with techniques like RLHF (Reinforcement Learning with Human Feedback) to reduce biases and make the models safer.
See this article for a good comparison of different (slightly early, as of January 2023) chat models. The GPT-4 technical report also talks about a technique called RBRM (Rule Based Reward Models) used to further align models beyond RLHF.
Another important consideration for models is their SLA and compliance guarantees. Does the model use your data to train their future versions? Do they provide the compliance levels that you have promised your customers? Do the models operate in a cloud environment that matches your customers' expectations for SLA and compliance?
Conclusion
Picking a chat model API for your development needs is an art that requires balancing many tradeoffs. I hope this article provided you with some tools to help with that.