Evaluating Local Models with Custom Datasets

I am currently working on generative AI, currently text+image experiences, educational AI generated visual guides in various mediums (comic, video, etc.). Before that, I was building llm apps with chat models, evaluating GPTs and Assistants API. Before that worked in conversational AI. Prior to that, have worked on many things product, software, AI, ML.
I wanted to share some information about comparing open local models.
I started with public benchmarks and leaderboards, even open and closed datasets, etc. - and got a sense of which models did well on these public benchmarks. But given these models are trained on a lot of public relatively uncurated data, many of the benchmarks have found their way into the models' memory, rendering the scores inaccurate. Even closed benchmarks have solutions shared publicly by users and these can find their way into the memory.
This post is about my informal opinionated experiment to evaluate local models against each other on a wide variety of questions.
The experiment
I queried about 98 models on a custom dataset of 160 varied questions. I then sampled the responses pairwise (approximately at random) for about 65k pairs to get the models' ELO ratings.
All the models were run locally on MacStudio with M2 Ultra and 192GB unified RAM. The largest model size was about 141GB in RAM.
The models were all called via ollama, and included recent ones from llama, deepseek (including r1-70b), qwen (including 2.5, but not the very recent 2.5 max), phi (including 3.5 and 4), mistral, nemotron, gemma, olmo2, tulu 3, and many others. Every model from these major families that had an open and permissive (commercial) license was evaluated.
The dataset had a wide variety of questions ranging from simple knowledge and arithmetic to complex coding, design and strategy to unsolved or open problems.
Pairwise comparisons/evals were done using PairRM. Most code was generated using cursor with a ton of AI code assistance.
Reminder: These are preliminary results, based on a very subjective pipeline customized to my own unique requirements, and were run to get an informal comparison. Future experiments will go into this in more detail.
Given the caveats, disclaimers above, here are some of the results.
And the winner is...
The top model was phi3.5:3.8b-mini-instruct-fp16 based on ELO rating.
A bit surprising as:
there were many much larger models which I expected to win.
the newer phi4 was behind (but only slightly behind) this model.
the models included the new deepseek-r1 - which but I am not sure if PairRM took into account in-response reasoning (
<think>section in deepseek-r1 responses) while evaluating.
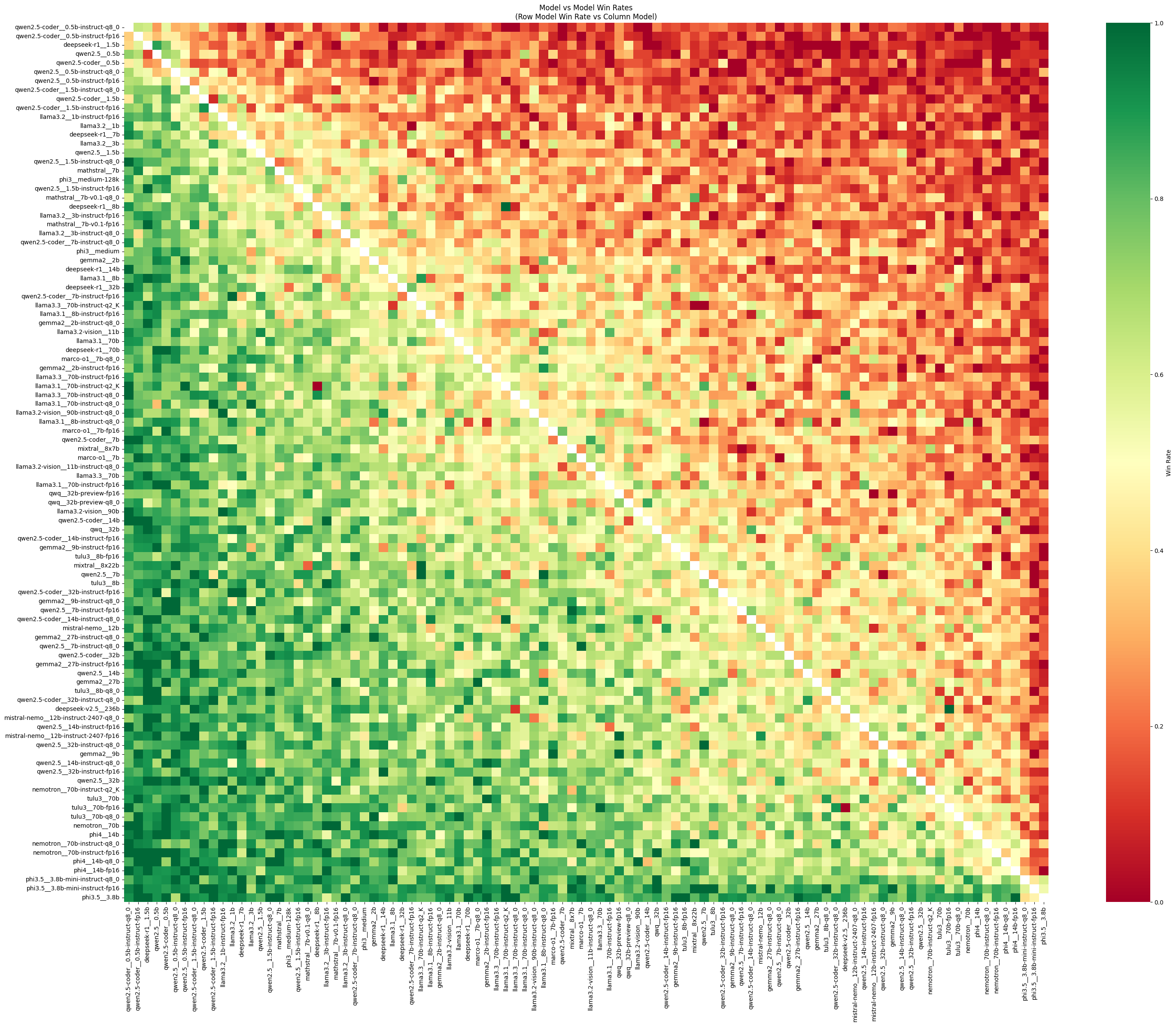
Models head to head performance
This heatmap shows how the models compared with each other:
how often the model on y axis won against the model on the x axis - green is more wins and red is more losses.
The vertical (y) axis shows the ranking of the models tested - models near the bottom are better, as you can see from the lot of greens in the bottom versus more reds as we go up.
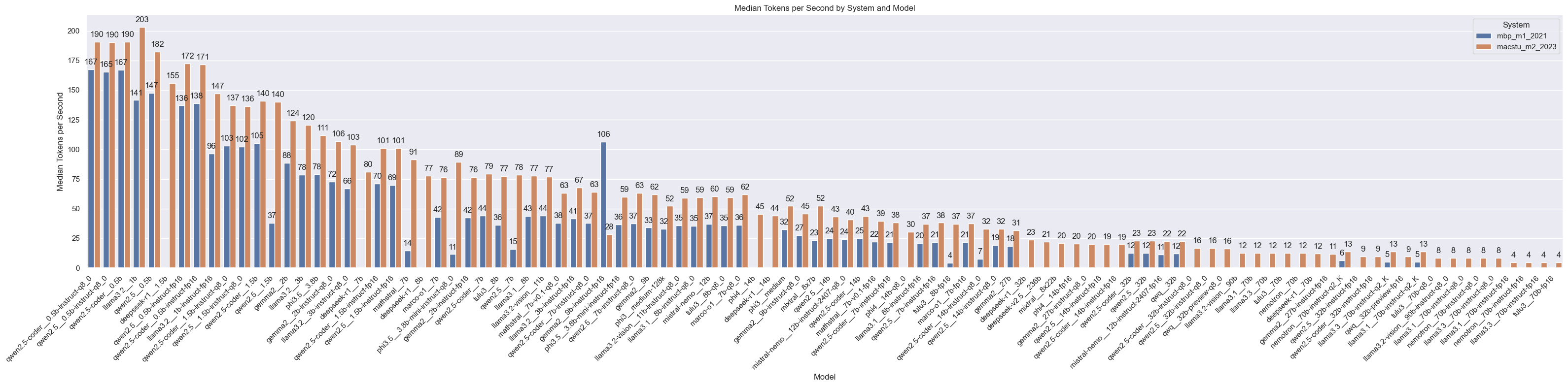
Model Throughputs
This bar chart shows the median tokens per second taken by each model - the orange bars show the results for the Mac Studio mentioned earlier - the blue bars are from a run on an older M1 Macbook Pro with 32 GB RAM. It ran a smaller subset of the models (some models would not fit, and newer models were not run on it). You can ignore the blue bars/M1 macbook pro.
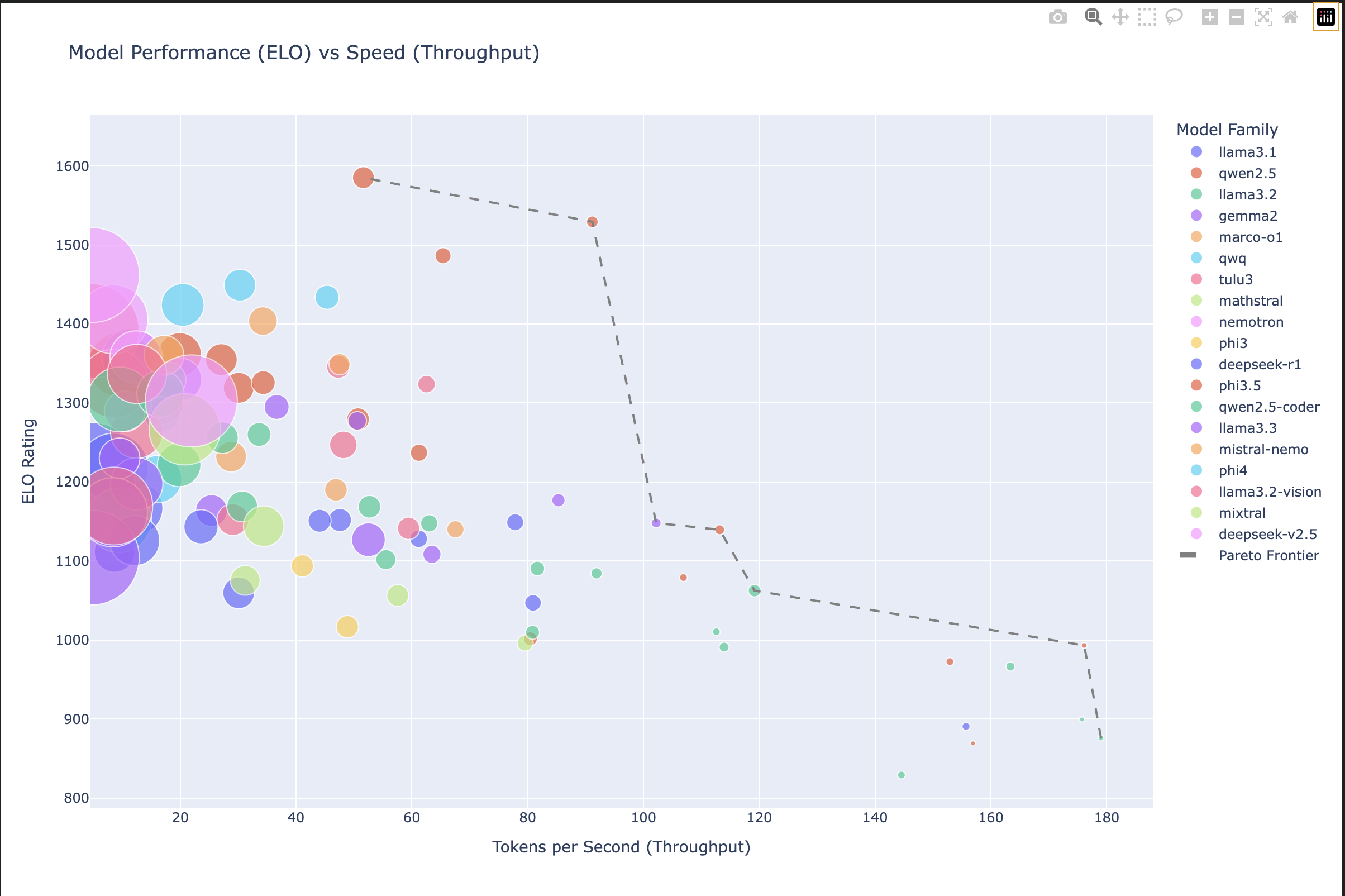
Model ELO vs Throughput
This scatter plot shows the models with ELO rating on the Y axis and the throughput on the Y axis. The Pareto frontier (the best ELO/throughput frontier) shows the best models at different values. The orange models at the top are all the top phi-3.5 variants. The size depicts the RAM required to load each model.
The interesting thing here is that small models seem to perform better than many larger models (within the constraints of this experiment).
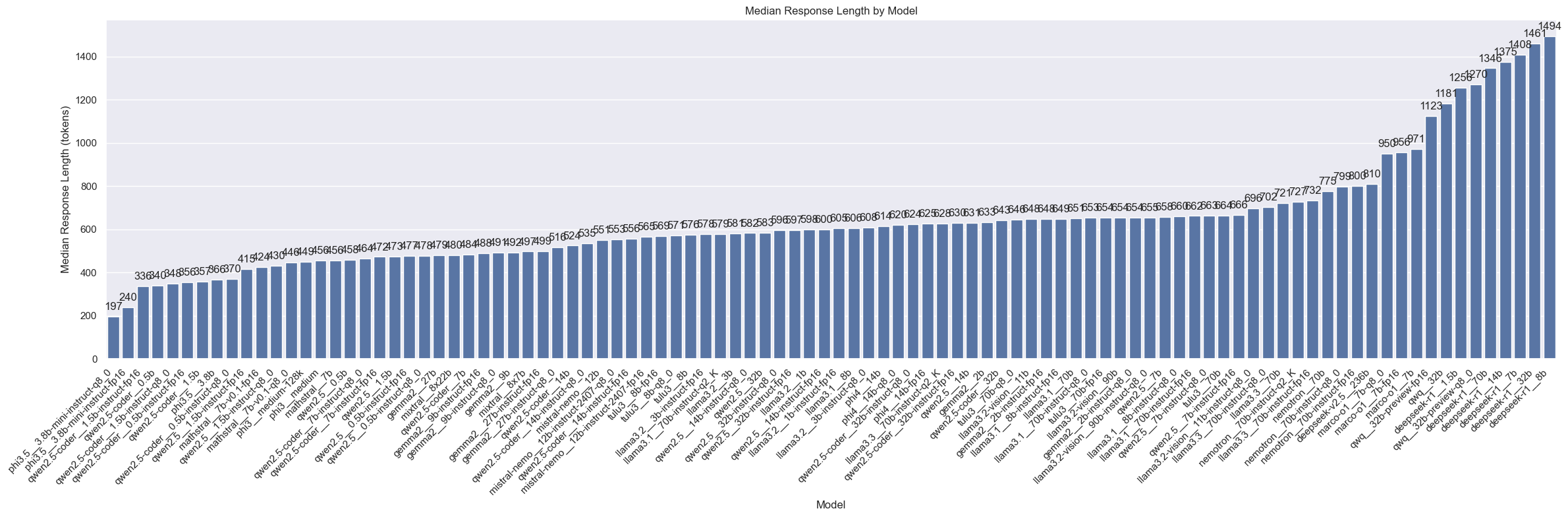
Response lengths by model
This shows which models have longer responses than others. As expected, the longest responses are from the reasoning models like deepseek-r1, qwq, marco-o1. The phi3.5 and some of the qwen code models have the shortest response lengths.
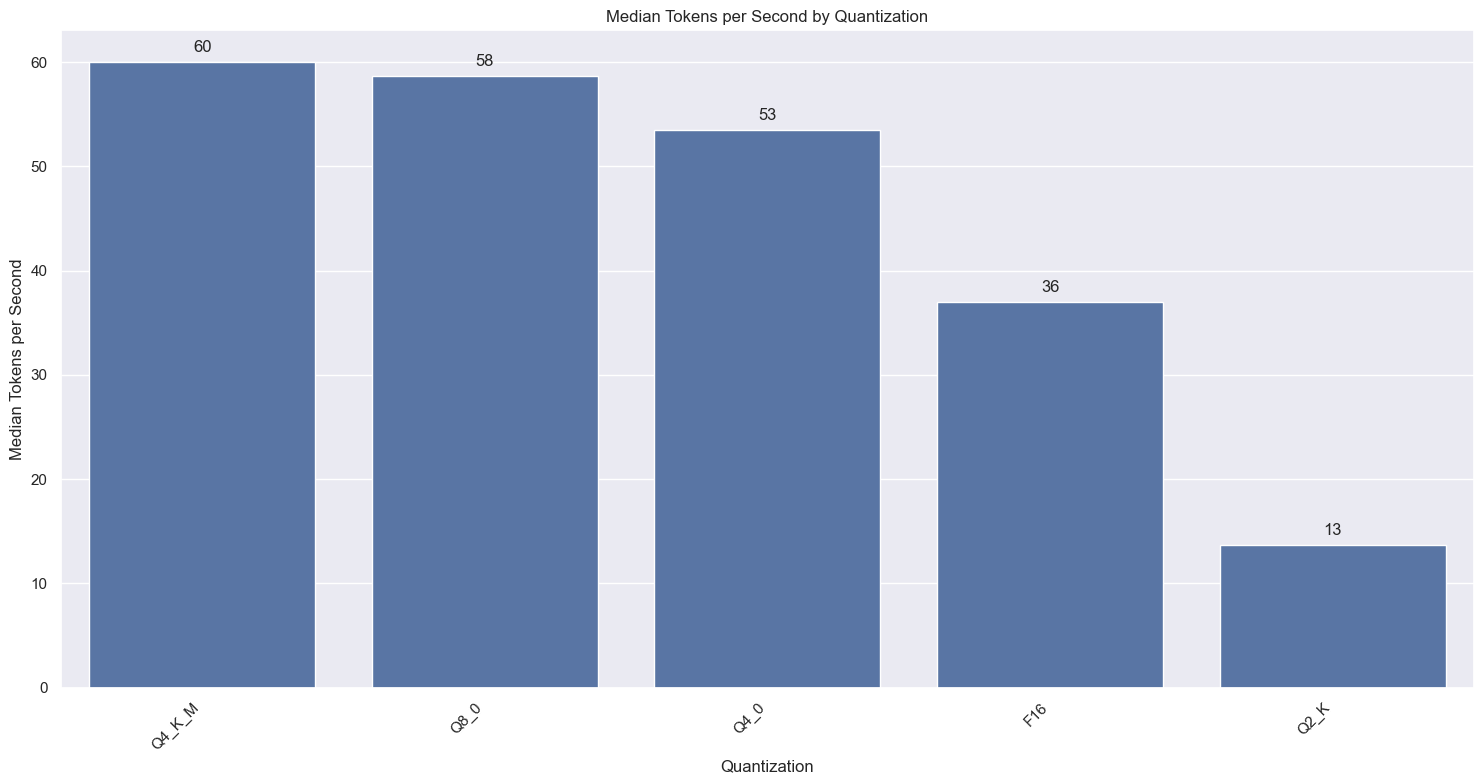
Quantization effect on throughput
We know that different quantizations have complex effects on the model speed. This graph shows that Q4_K_M (btw, this is usually the default for a model if no explicit quantization is specified in the tag) has the highest throughput. Haven't dug into this too much, but a possible hypothesis is that could be related to the fact that ollama defaults to Q4_K_M and has a lot of optimizations built to make this setup work well. But this dataset is imbalanced - some of these like Q2_K have very few models (only 3), so we should probably drop those.
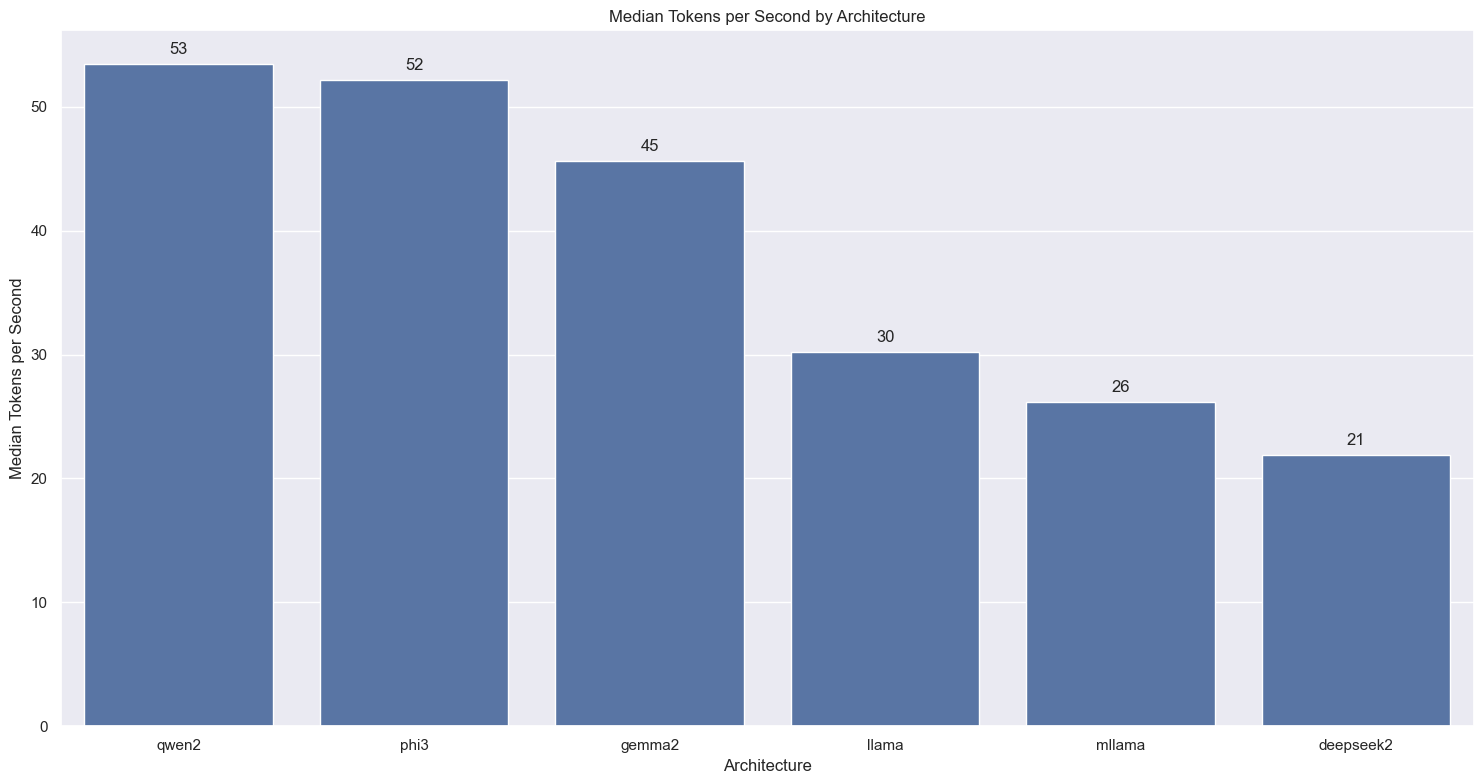
Throughput by Architecture
Qwen and Phi based models are the fastest responders - deepseek is the slowest.
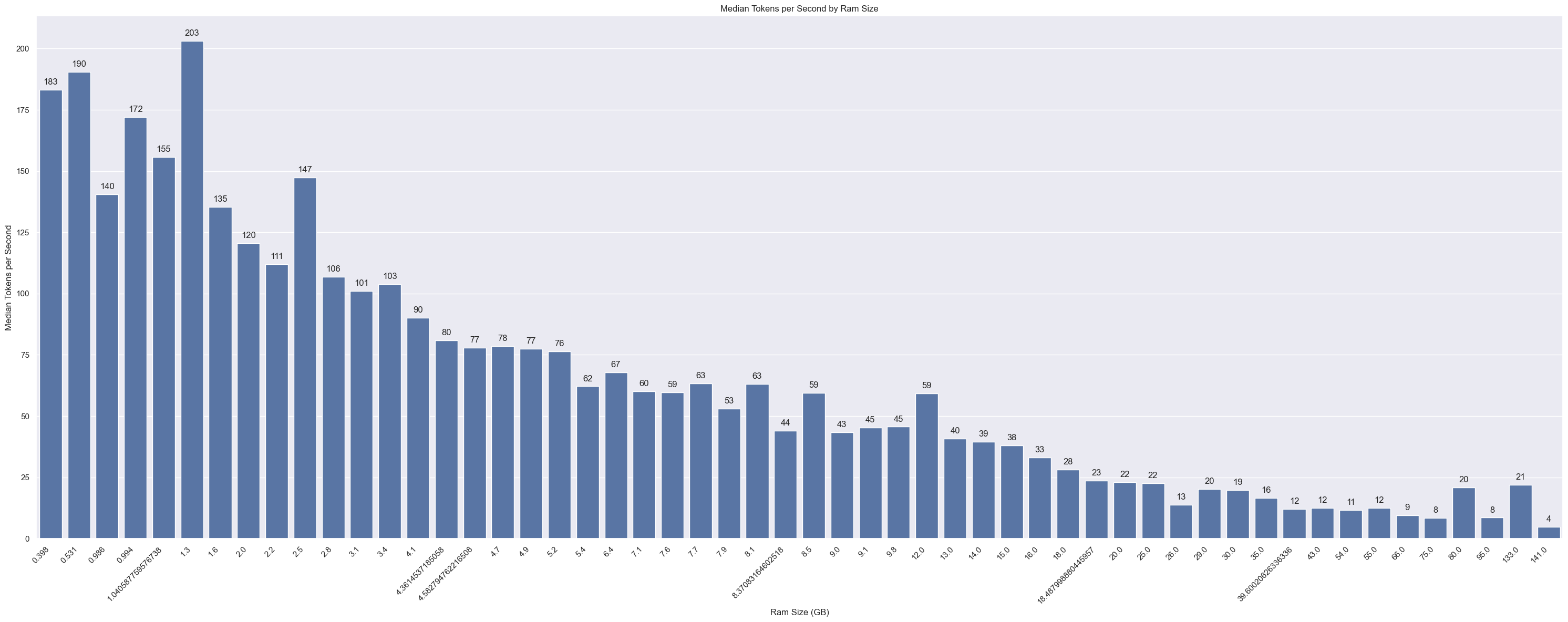
Throughput by RAM
Smaller models are generally higher throughput
A note about hardware
The best machine for most people to run models locally is this Mac Studio M2 Ultra with 192 GB RAM - RAM is often the bottleneck. For more details on this, please see local models in my earlier post.
Nvidia has powerful GPUs in the cloud, but the best local machine GPUs from Nvidia support only 24-32GB RAM. There are pricier configurations that combine multiple Nvidia GPUs, but they are way more expensive than the Mac Studio.
Unfortunately, Macs are not very conveniently available on the cloud - as of today, I would experiment locally on Mac, and deploy to Nvidia GPUs in the cloud for use cases that need it to run in the cloud.
Public benchmarks
For much more elaborate comparisons of local and hosted llms, my favorite site nowadays is https://artificialanalysis.ai/ - they compare llms, llm api providers and also have comparisons for other modalities like image and audio.
Conclusion
So, that's it - these are the results from my own custom experiments on local models running on Apple Silicon. I reiterate that these are for a very custom pipeline, and may not directly translate to your data and use cases. I am sharing this mainly because I did not see any such comparison of local llms that are not based on standard benchmarks.
And finally…
Support me: The best way to support my continued work (articles, research, new AI based experiences) is via ko-fi. Please let me know your feedback, and what you would like to see more of in the future. Thank you!

